Web Scraping Books on Goodreads Using Python

Books have always been a valuable source of knowledge, entertainment, and culture. With the rise of online bookstores, digital libraries, and review platforms, accessing book-related information has become easier than ever. However, manually gathering details like book titles, authors, prices, ratings, and reviews from multiple websites can be time-consuming.
In this project, we’re diving into Goodreads, one of the largest online book platforms for readers and book recommendations and using web scraping to collect valuable book data. From bestselling titles to user reviews, we’ll extract and analyze a wide range of insights.
Why Goodreads?
Goodreads isn’t just a place for book reviews — it’s is a goldmine for book lovers, offering an abundance of valuable data that goes beyond just book titles. With millions of users contributing reviews, ratings, and recommendations, it’s the perfect platform to tap into real-time reading trends and preferences. It’s packed with rich data about:
📖 Books, Authors, and Summaries
⭐ Ratings & Reviews.
📚 Genres & Recommendations.
Outline of the article
- Retrieve the webpage using
requests. - Parse the HTML content with
BeautifulSoup. - Extract the book title, author, and relevant metadata.
- Compile the data and save it into a CSV file.
- Analyze and visualize the data collected.
Setting up the Scraping Environment
Tools needed for this project:
- Python: Ensure python is installed on your system.
- Libraries: Install the required libraries, such as BeautifulSoup and requests.
Requestsis a Python library used to send HTTP requests and retrieve webpage content, like HTML or JSON.BeautifulSoupis a library that parses HTML or XML content, allowing you to navigate and extract specific elements (like titles, links, or images) from the webpage.
3. PowerBI: For Data transformation and visualization.
pip install requests
pip install beautifulsoup4 as bs4
Then import the libraries already installed.
import requests
from bs4 import BeautifulSoupRetrieve the webpage using requests
The pages used covers top 10 rated books with over 10,000 ratings covering spanning across various genres.
The first step in web scraping is to download the HTML content of the webpage. This is done by sending an HTTP request to the website’s URL. To retrieve the content from the page on Goodreads, we send a get request using the requests library.
page = requests.get(
"https://www.goodreads.com/list/show/153860.Goodreads_Top_100_Highest_Rated_Books_on_Goodreads_with_at_least_10_000_Ratings").contentParse the HTML content with BeautifulSoup
The HTML source code is parsed using BeautifulSoup. This allows for navigating the page’s structure and extracting the necessary data. The content retrieved in the previous step is used to create a BeautifulSoup object to process the HTML.
soup = BeautifulSoup(page,"html.parser")Extract the book title, author, and relevant metadata
Before extracting the book title, author, and relevant metadata, it’s essential to inspect the HTML structure of the webpage. This helps identify the correct tags and classes that contain the desired data.
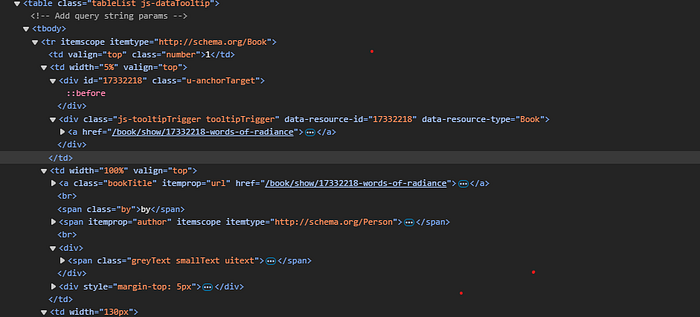
Once the relevant tags are identified, Beautiful Soup’s methods can be used to extract the required information. The <div> tag with the "left" class contains the necessary details, as shown in the image above. To extract specific parts of the HTML, the find() or find_all() methods can be used. Additionally, specifying the class of the tag helps narrow down the results.
This will print the required HTML from the first book in the list i.e. words of radiance.
cards = soup.find("table",class_="tableList js-dataTooltip").find_all("tr")
for card in cards:
try:
book_link= card.find ("a",itemprop="url")["href"]
print(book_link)
single_book_link= requests.get(f"https://www.goodreads.com{book_link}").content
soup = BeautifulSoup(single_book_link, "html.parser")
book_publication = soup.find("p", {"data-testid": "publicationInfo"})
book_publication = None if book_publication == None else book_publication.text.strip()
book_genre= soup.find("span", class_="BookPageMetadataSection__genreButton").text.strip()
book_info= soup.find("script", {"type": "application/ld+json"})
book_info = None if book_info == None else book_info.text.strip()
book_info_json = json.loads(book_info)
book_title= book_info_json.get("name")
book_image =book_info_json.get("image")
book_format= book_info_json.get("bookFormat")
book_num_of_pages= book_info_json.get("numberOfPages")
book_in_language= book_info_json.get("inLanguage")
book_isbn = book_info_json.get("isbn")
book_awards= book_info_json.get("awards")
book_author = book_info_json.get("author")
book_aggregate_rating=book_info_json.get("aggregateRating")
book_rating_value= book_aggregate_rating.get("ratingValue")
book_rating_count= book_aggregate_rating.get("ratingCount")
book_review_count= book_aggregate_rating.get("reviewCount")
books.append({"book_title":book_title,
"book_image":book_image,
"book_format":book_format,
"book_num_of_pages":book_num_of_pages,
"book_in_language":book_in_language,
"book_isbn":book_isbn,
"book_awards":book_awards,
"book_author":book_author,
"book_publication": book_publication,
"book_genre": book_genre,
"book_rating_value": book_rating_value,
"book_rating_count":book_rating_count,
"book_review_count":book_review_count
})
print({"book_title":book_title,
"book_image":book_image,
"book_format":book_format,
"book_num_of_pages":book_num_of_pages,
"book_in_language":book_in_language,
"book_isbn":book_isbn,
"book_awards":book_awards,
"book_author":book_author,
"book_publication": book_publication,
"book_genre": book_genre,
"book_aggregate_rating":book_aggregate_rating,
"book_rating_value": book_rating_value,
"book_rating_count":book_rating_count,
"book_review_count":book_review_count
})
except Exception as e:
print(e)Compile the data and save it into a CSV file.
After extracting the data, it is structured and saved into a CSV file using Python’s csv.DictWriter(), ensuring all book details are properly formatted. Additionally, any failed extractions are stored in a JSON file using json.dump(), allowing for further review and debugging.
keys = books[0].keys()
with open("books.csv","w",newline="",encoding="UTF-8") as f:
writer = csv.DictWriter(f,keys)
writer.writeheader()
writer.writerows(books)
print("Done!")
with open('failed_json.json', 'w') as f:
# where data is your valid python dictionary
json.dump(failed_books, f)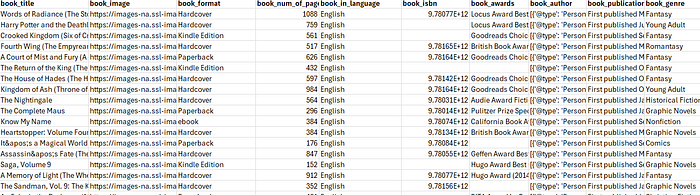
Analyze and Visualize the Collected Data
The extracted data is then imported into a visualization tool for analysis. In this project, Power BI was used to create visual representations of the data.
Data cleaning: After importing the data into Power BI, data cleaning and transformation are performed using Power Query to refine and structure the dataset. Once cleaned, the data is used for visualization to uncover meaningful insights.
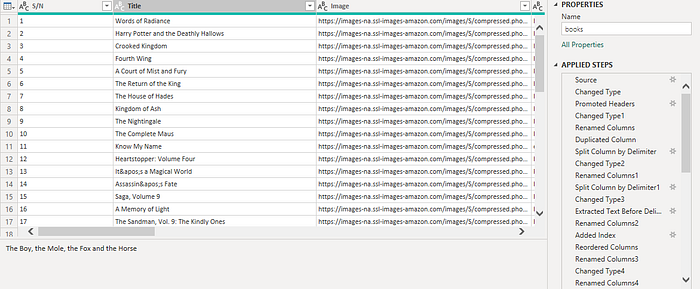
Data visualization
This was accomplished using Power BI to visualize the information through charts and graphs.
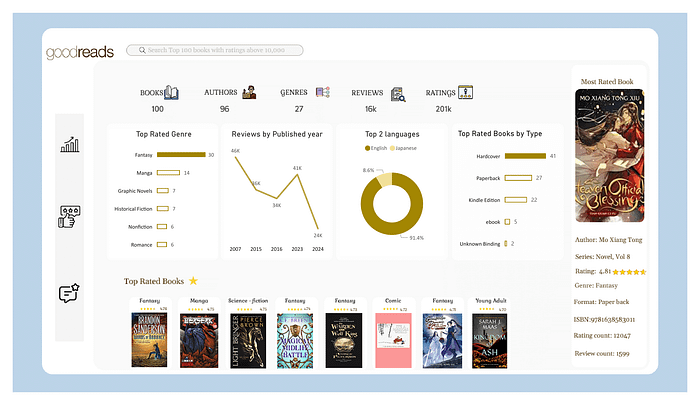
Notable takeaway:
- “Heaven’s Official Blessing” by Mo Xiang Tong, a fantasy genre book, received the most ratings, with a total of 12,047 ratings and 1,599 reviews.
- he highest-rated genre was fantasy
- English was the most preferred language.
- Hardcover was the most popular book format
- The number of reviews declined over time, with a peak in 2023 followed by a drop in 2024.
